Introduction
Deux ordinateurs placés sur un même réseau sont en mesure de s’échanger de l’information : un ordinateur A demande des ressources (fichiers de texte, images, vidéos, son…) à un ordinateur B qui les lui fournit.
Mais avant de s’échanger des données, ils doivent savoir si ils « parlent » le même langage.

A voir dans ce cours
Autres cours à consulter
Ce qui suit ci-dessous est fortement inspiré des travaux proposés par David Roche (enseignant en lycée) sur son site pixees.fr
Le Client & le Serveur
Le client
L’ordinateur A est appelé dans notre cas le client.
Le client, c’est l’internaute lambda : nous. Il possède un terminal (ordinateur, tablette, smartphone, TV…).
Plusieurs clients peuvent s’adresser simultanément à un serveur.
Le serveur
L’ordinateur B est appelé le serveur.
Le serveur est un ordinateur muni de capacités supérieures :
- grand volume de stockage
- fonctionnement 24h sur 24 pour assurer une continuité de service.
Les sociétés comme Google possèdent des milliers de serveurs qui mutualisent « leurs forces » pour répondre aux milliers de requêtes simultanées qu’ils reçoivent des clients du monde entier.
Ces serveurs sont rassemblés dans d’immenses bâtiments dédiés que l’on appelle des datacenters.
Un exemple de serveur : le serveur Web
Un serveur web contrôle la façon dont les clients peuvent accéder aux fichiers hébergés sur ce serveur. On y trouvera a minima :
- un logiciel qui consigne les URL : adresse (=chemin) des pages d’un site web (=fichiers html ou css ou js…).
- le protocole HTTP : il utilisé par le navigateur et le serveur pour communiquer et afficher les pages web. Plus de détails à la fin de cette page.
Article à lire pour répondre aux questions
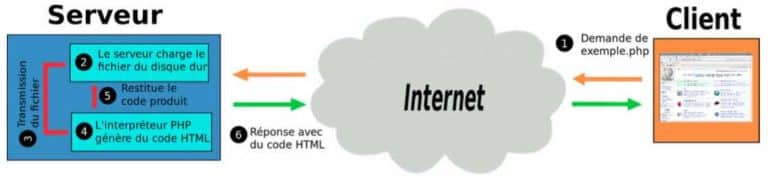
Le modèle interaction Client / Serveur
A chaque fois qu’un navigateur (ordinateur A) a besoin d’un fichier hébergé sur un serveur web, le navigateur va demander (= envoyer une requête) ce fichier via le logiciel HTTP. Quand la requête atteint le bon serveur web (ordinateur B), le serveur HTTP (logiciel) renvoie le document demandé, également grâce à HTTP.

Du statique au dynamique
Au début du web, les sites étaient dits statiques : le concepteur du site écrivait son code HTML qui restait statique. Il était envoyé en l’état par le serveur HTTP au client.
Aujourd’hui la plupart des sites sont dits dynamiques car les serveurs web sont dotés d’un autre composant logiciel capable de générer du code HTML en fonction des requêtes du client.
C’est le cas des serveurs d’applications : site internet qui possède toutes les fonctionnalités d’une application ( par exemple GeoGebra en ligne ou Scratch 3) et/ou des serveurs qui gèrent une base de données.
Le langage le plus courant permettant de générer dynamiquement du code est PHP (Hypertext Pre- processor) qui ne fonctionne qu’à condition que le serveur soit équipé du composant PHP.
D’autres langages peuvent fonctionner côté serveur : Python, Java…
<h1>Bienvenue sur mon site </h1>
<p>Il est ',$heure,'</p>
<h1>.................................</h1>
<p>.................................</p>Le protocole HTTP
Par quoi commence toujours une adresse URL ? (répondre à la question sur votre fiche)
Qu'est ce qu'un protocole ?
Un protocole est l’ensemble des règles qui permettent à deux ordinateurs de communiquer.
HTTP (HyperText Transfert Protocol) va permettre au client d’effectuer des requêtes à destination d’un serveur web. En retour, le serveur web va envoyer une réponse.
Voici de façon simplifiée l’enchaînement des indications données au serveur par un client qui envoie une requête :
- la méthode employée pour effectuer une requête (voir ci-dessous)
- l’URL de la ressource (le chemin qui emmène au répertoire qui la contient)
- la version du protocole utilisé par la client (souvent HTTP 1.1)
- le navigateur employé (par ex. Firefox) et sa version
- le type de document demandé (par ex. HTML)
- …
La requête HTTP du client (ordinateur A)
Exemple de requête HTTP :
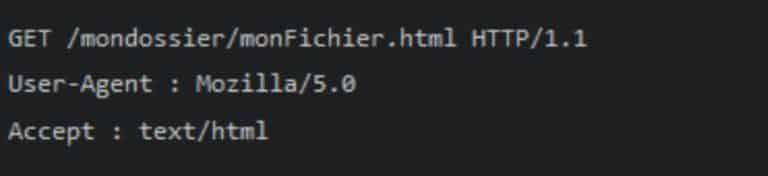
Nous avons ici plusieurs informations :
- « GET » est la méthode employée (voir ci-dessous)
- « /mondossier/monFichier.html » correspond l’URL de la ressource demandée
- « HTTP/1.1 » : la version du protocole est la 1.1
- « Mozilla/5.0 » : le navigateur web employé est Firefox de la société Mozilla
- « text/html » : le client s’attend à recevoir du HTML
Revenons sur la méthode employée : Une requête HTTP utilise une méthode : c’est une commande qui demande au serveur d’effectuer une certaine action. Voici la liste des méthodes disponibles :
GET, HEAD, POST, OPTIONS, CONNECT, TRACE, PUT, PATCH, DELETE
Détaillons 4 de ces méthodes :
- GET : C’est la méthode la plus courante pour demander une ressource. Elle est sans effet sur la ressource.
- POST : Cette méthode est utilisée pour soumettre des données en vue d’un traitement (côté serveur). Typiquement c’est la méthode employée lorsque l’on envoie au serveur les données issues d’un formulaire.
- DELETE : Cette méthode permet de supprimer une ressource sur le serveur.
- PUT : Cette méthode permet de modifier une ressource sur le serveur
La réponse envoyée par le serveur (ordinateur B)
Une fois la requête reçue, le serveur va envoyer une réponse.
Voici un exemple de réponse :
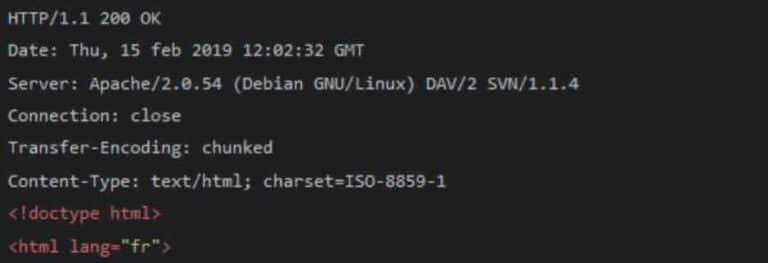
La première ligne :
- Elle reprend la version HTTP : 1.1
- Elle contient également un code : 200, qui indique que le document recherché par le client a bien été trouvé par le serveur (si code 404 : le document demandé n’est pas trouvé)
La troisième ligne :
Elle indique le type le serveur auquel le client s’adresse : il s’agit ici d’un serveur Apache installé sur une distribution GNU/Linux nommée Debian. Apache est le serveur web le plus courant dans le monde. Il en existe bien d’autres.
Sécurité web = protocole https
Depuis le début des années 2010, le protocole HTTPS s’est généralisé sur le réseau mondial. Il s’agit de la version « sécurisée » du protocole HTTP.
Par « sécurisé » en entend que les données sont chiffrées (codées) avant d’être transmises sur le réseau. Seul le possesseur de la clé de déchiffrement sera en mesure de lire les données transmises sur le réseau.
Ce protocole sécurisé est apparu lorsque des données sensibles ont commencé à circuler sur la toile telles que des données personnelles sur les réseaux sociaux, des coordonnées bancaires, des déclarations de revenus etc…
D’un point vu strictement pratique il est nécessaire de bien vérifier que le protocole est bien utilisé (l’adresse commence par « https« ) avant de transmettre des données sensibles.
Si ce n’est pas le cas, passez votre chemin, car toute personne qui interceptera les paquets de données sera en mesure de lire vos données sensibles.
Exercice - Les serveurs web
Travail : Faire une recherche sur le web et citer 3 serveurs web open source avec leur fréquence d’utilisation sur les serveurs sur World Wide Web